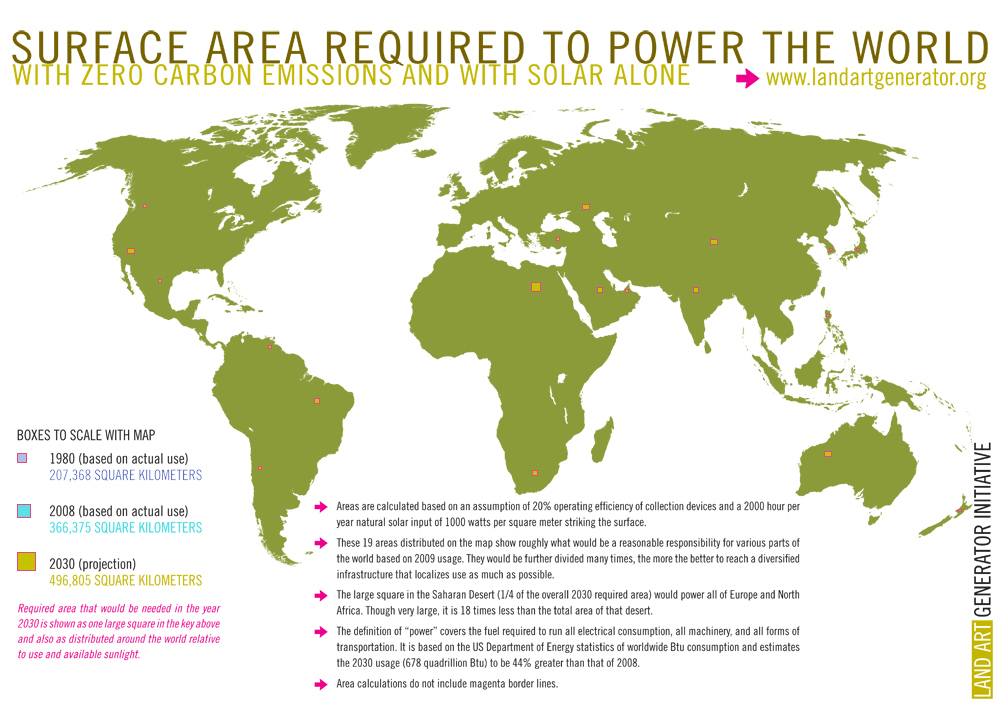
| Huh!?! |
First statistics is the backbone of modern scientific work. Because of the complexity involved in modern research and the importance of major breakthroughs we need to collect tons of data. Modern experiments simply aren't aiming at low hanging scientific fruit anymore and potential gains may be almost minimal or indistinguishable from background noise. So, we collect data, lots and lots of data. On any study there may be thousands or even millions of data points to sort through and process and statistics is how we do that.
The assumption of statistics is that if there was an absolute value to something that you could measure, you would never measure that exact value every time no matter how accurate your instrument. Assuming you had an infinite number of measurements even though they weren't all the same, the average or mean of the sample should represent the true value. Clearly an infinite number of measurements is impractical for reasons of both time and money so we use statistics to give us an idea of what that mean could be with the data we can gather. Think of it kind of like a plinko distribution.
| Statistics: making game shows boring since forever |
Any one of those balls could end up in any one of those slots when dropped but the overwhelming majority will end up in the middle. So how do we use that in science? There are essentially two ways that statistics gets heavily used.
The first is to essentially try to find a connection between an observed result and a bunch of possible variables. We're essentially looking for a correlation between variables. So for instance I have two cats and Id like to test to see how I can make them more cuddly (wicked gay experiment I know bear with me). So I'm attempting to figure out what triggers the desired behavior from the following variables: how much food they eat, the sugar content of the food, how much sleep they get, how recently they took a bath and positive reinforcement. At the conclusion of my experiment I can test each variable for a relationship to my target behavior (cuddles). If I find a relationship between baths and positive reinforcement but no others I can rule out food sugar and sleep. Now assuming this relationship is positive on both accounts that doesn't mean that continuous baths or treats will always yield more cuddles, it means that further testing is required under more controlled circumstances.
If you said aha you were limited in what potential options could affect the outcome congrats gold star to you. If you said ahaha that proves crap, their may be influences like free will that essentially nullifies the experiment except in the broadest sense you get a 1 UP mushroom because your awesome.
| Yay Video games |
What you just stumbled upon is the golden rule of statistics and also the most frequently ignored. CORRELATION DOES NOT AND WILL NOT EVER PROVE CAUSATION. The closest you can get is a single variable system like say pushing a toy car AND you can link the effect to the cause with a mathematical relation. See the second rule surrounding correlations is they can only be found using straight lines.Those lines can be mathematically rearranged to be straight but at the end of the day they have to be straight and they have to be lines. If you don't follow those rules bias is likely to creep in and you can find whatever you want to see. So when you see people linking
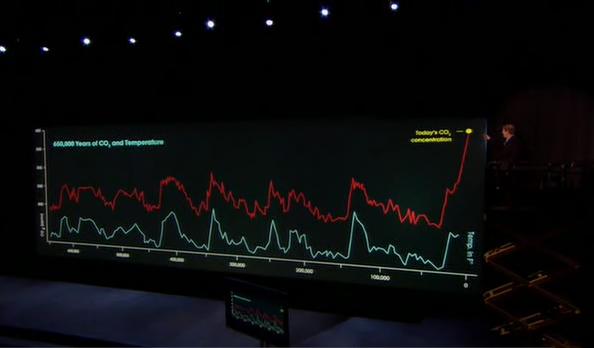
To This
Its kind of, sort of shoddy statistics. See the lines both go up and they both seem to be on an exponential ish curve but there is a hell of a lot more variability in one than the other. That's not to say that they cant be linked or shouldn't be linked but that temperature data needs to be cleaned up a lot. That's right folks it's a climate change article huzzah. Which brings us to the second major use of statistics in science, prediction.
See once we have our theories we need to test those theories, this is science after all not psychology (that link remains until Carol Gilligans crackpot theories with no evidence are cast out from textbooks, I can hold a grudge quite well Westfield (-.-)). So once we have a working model; one that cleans up all the data and variables to show the trends as clearly correlated; we need to test that hypothesis and model. In the case of climate change that is done by both back casting climate, and attempting to forecast it. But how do we know if were right and not just making some crap up. Well prepare for a fun lesson in statistics.
| Normal Distribution |
Above you see whats called a normal distribution curve. It's not really useful as it technically doesn't exist (outside of math and theory), but it is the base of all statistics, gaze upon it. The numbers on the bottom of the curve represent whats called a standard deviation. Each standard deviation away from the midpoint/zero/base point contains more of the data as a direct percentage of a theoretical infinite sample size. You can see those percentages within the brackets, so within half of a standard deviation 38.2 percent of the total data is contained, 19.1% on both the left and the right.
You may have heard of the 95% confidence interval or statistical significance (hint: its what this terribly boring thing is about). While arbitrary, it essentially means that 95% of my collected data should fit within about 1.66 standard deviations from the mean. So when testing a theory the mean is my hypothesized value and the standard deviation is my error typically reported as a +/- value or percentage of the hypothesis. There is actual math to determine your standard deviation it is not a guess value and cannot be arbitrarily changed because your data doesn't line up. When determining significance, what we are essentially saying is the probability of the data matching our mean by chance is 5% or less.
So lets put all of this together for hypothesis testing. Let's say I made the claim that I was like a human thermometer. Not only could I tell your temperature, I could do so merely by looking at you and my accuracy would be within +/- .1 degrees Fahrenheit. It's an awesome claim so we design an experiment, we take 1000 volunteers who I simply look at through a photograph. The temperature of all participants is taken at the same time of the photographs. So I proclaim every single photograph has a temperature of 98.6 degrees (this is the natural average anyways). Now lets say the actual data lies within +/- 1 degree rather than the +/- .1 degrees I claim. My proclaimed accuracy is essentially falsified. Even if the mean of all those temperatures is 98.6, and the accuracy is correct, it still doesn't prove my claim that I can accurately tell human temperature from appearance. This is a demonstration of correlation vs. causation error.
So lets put all of this together for hypothesis testing. Let's say I made the claim that I was like a human thermometer. Not only could I tell your temperature, I could do so merely by looking at you and my accuracy would be within +/- .1 degrees Fahrenheit. It's an awesome claim so we design an experiment, we take 1000 volunteers who I simply look at through a photograph. The temperature of all participants is taken at the same time of the photographs. So I proclaim every single photograph has a temperature of 98.6 degrees (this is the natural average anyways). Now lets say the actual data lies within +/- 1 degree rather than the +/- .1 degrees I claim. My proclaimed accuracy is essentially falsified. Even if the mean of all those temperatures is 98.6, and the accuracy is correct, it still doesn't prove my claim that I can accurately tell human temperature from appearance. This is a demonstration of correlation vs. causation error.
| Artists depiction of me reading temperature |
So how do we apply this to climate change? Well lets assume that I have a model projection of what the global average temperature should be (my mean) and because I'm super smart I did all the very painful (it truly is excruciating) math to determine my error (the standard deviation). In order for me to be correct about both my mean and standard deviation, 95% of the sample data should fit within 1.66 times my standard error from the mean. If the data is scattered so as not to be significant either the hypothesis, the margin of error or both are incorrect. That's assuming the data is scattered outside of both tails of the curve. If however the data is scattered only outside of one tail (like being below all estimates) then we can say that the probability of the hypothesized mean being correct is less than 2.5%. So the probability that climate change/global warming/extreme weather forecast predictions and models accurately depict the future is less than 2.5%. Think about that for a moment.
Out of 34 models when the estimates are averaged together (a reasonable practice with a multiple estimate scenario) actual temperature is below the predicted temperature below the level of significance and has been for almost 18 years. Now almost all of these models don't find significance on their own, only a few actually show some significance with actual data. So in short the probability that the settled science, that the claims for trillions of dollars in alternative energy are neccessary to avoid catastrophe, have a less than 2.5% chance of being correct. I have mentioned the precautionary principle but frankly that's just absurd.
So how do climatologists plan on handling observational discrepancies? Well I know I have faced this challenge with computer models that I designed and my response was to start from scratch; I'm also fairly rigid in how math and science should be applied. One potential solution to the discrepancy is to expand the margins of error for the estimates. An interesting choice considering the largest criticism of climatologists is that they are overstating their confidence and position. The other is to wait for more data.
These choices bring about other issues aside from the due chiding in the public arena; and proof that the science isn't as settled as is claimed). They can only expand those uncertainties so much before the models predict cooling, warming and no temperature change at all.
If' your theory is proven correct by all potential outcomes it is not falsifiable. If a theory is not falsifiable than it is no better than a religion.
These choices bring about other issues aside from the due chiding in the public arena; and proof that the science isn't as settled as is claimed). They can only expand those uncertainties so much before the models predict cooling, warming and no temperature change at all.
If' your theory is proven correct by all potential outcomes it is not falsifiable. If a theory is not falsifiable than it is no better than a religion.